Note: This post will be a bit different from the previous ones. It’s intended to provide brief history as to why current NativeScript for Android implementation is designed this way. So, this post will be most useful for my Telerik ex-colleagues. Think of it as kind of historic documentation. Also, it is a chance to have a peek inside a developer’s mind 😉
I already gave you a hint about my current affairs. Since February I took the opportunity to pursue new ventures in a new company. The fact that my new office is the very next building to Telerik HQ gives me an opportunity to keep close connections with my former colleagues. At one such coffee break I was asked about the current memory management implementation. As I am no longer with Telerik, my former colleagues miss some important history that explains why this feature is implemented this way. I tried to explain briefly that particular technical issue in a previous post, however I couldn’t go much in depth because NativeScript was not announced yet. So, here I’ll try to provide more details.
Note: Keep in mind that this post is about NativeScript for Android platform, so I will focus only on that platform.
On the very first day of the project, we decided that we should explore what can be done with JavaScript-to-Java bidirectional marshalling. So, we set up a simple goal: make an app with a single button that increments a counter. Let’s see what Android docs says about button widget.
public class MyActivity extends Activity {
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.content_layout_id);
final Button button = findViewById(R.id.button_id);
button.setOnClickListener(new View.OnClickListener() {
public void onClick(View v) {
// Code here executes on main thread after user presses button
}
});
}
}
After so many years, this is the first code fragment you see on the site. And it should be so. This code fragment captures the very essence of what button widget is and how it is used. We wanted to provide JavaScript syntax which feels familiar to Java developers. So, we ended up with the following syntax:
var button = new android.widget.Button(context);
button.setOnClickListener(new android.view.View.OnClickListener({
onClick: function() {
// do some work
}
}));
This example is shown countless times in NativeScript docs and various presentation slides/materials. It is part of our first and main test/demo app.
Motivation: we wanted to provide JavaScript syntax which is familiar to existing Android developers.
This decision brings an important implication, namely the usage of JavaScript closures. To understand why closures are important for the implementation, we could take a look at the following simple, but complete, Java example.
package com.example;
import android.app.Activity;
import android.os.Bundle;
import android.view.View;
import android.widget.Button;
import android.widget.LinearLayout;
import android.widget.TextView;
public class MyActivity extends Activity {
private int count = 0;
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
LinearLayout layout = new LinearLayout(this);
layout.setFitsSystemWindows(false);
layout.setOrientation(LinearLayout.VERTICAL);
final TextView txt = new TextView(this);
layout.addView(txt);
Button btn = new Button(this);
layout.addView(btn);
btn.setText("Increment");
btn.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
txt.setText("Count:" + (++count));
}
});
setContentView(layout);
}
}
Behind the scene, the Java compiler will generate anonymous class that we can decompile and inspect closely. For the purpose of this post I am going to use fernflower decompiler. Here is the output for MyActivity$1 class.
package com.example;
import android.view.View;
import android.view.View.OnClickListener;
import android.widget.TextView;
class MyActivity$1 implements OnClickListener {
// $FF: synthetic field
final TextView val$txt;
// $FF: synthetic field
final MyActivity this$0;
MyActivity$1(MyActivity this$0, TextView var2) {
this.this$0 = this$0;
this.val$txt = var2;
}
public void onClick(View view) {
this.val$txt.setText("Count:" + MyActivity.access$004(this.this$0));
}
}
We can see the Java compiler generates code that:
1) captures the variable txt
2) deals with ++count expression
This means that the click handler object holds references to the objects it accesses in its closure. We can call this class stateful as it has class members. Fairly trivial observation.
Let’s take a look again at the previous JavaScript code.
var button = new android.widget.Button(context);
button.setOnClickListener(new android.view.View.OnClickListener({
onClick: function() {
// do some work
}
}));
We access the button widget and call its setOnClickListener method with some argument. This means that we should have instantiated Java object which implements OnClickListener so that the button can use it later. You can find the class implementation for that object in your project platform directory
[proj_dir]/platforms/android/src/main/java/com/tns/gen/android/view/View_OnClickListener.java
Let’s see what the actual implementation is.
package com.tns.gen.android.view;
public class View_OnClickListener
implements android.view.View.OnClickListener {
public View_OnClickListener() {
com.tns.Runtime.initInstance(this);
}
public void onClick(android.view.View param_0) {
java.lang.Object[] args = new java.lang.Object[1];
args[0] = param_0;
com.tns.Runtime.callJSMethod(this, "onClick", void.class, args);
}
}
As we can see this class acts as a proxy and doesn’t have fields. We can call this class stateless. We don’t store information that we can use to describe its closure if any.
So, we saw that Java compiler generates classes that keep track of their closures while NativeScript generates classes that don’t keep track of their closures. This is a simple implication due to the fact the JavaScript is a dynamic language and the information of lexical scope is not enough to provide full static analysis. The full information about JavaScript closures can be obtain at run time only.
The ovals diagram I used in my previous post visualize the missing object reference to the closed object. So, now we have an understanding what happens in NativeScript runtime for Android. The current NativeScript, at the time of writing version 3.3, provides mechanism to “compensate” for the missing object references. To put it simply, for each JavaScript closure accessible from Java we traverse all reachable Java objects in order to keep them alive until the closure becomes unreachable from Java. Well, while we were able to describe the current solution in a single sentence it doesn’t mean it doesn’t have drawbacks. This solution could be very slow if an object with large hierarchy, like global, is reachable from some closure. If this is the case, the implication is that we will traverse the whole V8 heap on each GC.
Back then in 2014, when we hit this issue for the first time, we discussed the option to customize part of the V8 garbage collector in order to provide faster heap traversing. The drawback is slower upgrade cycle for V8 which means that JavaScriptCore engine will provide more features at given point in time. For example, it is not easy to explain to the developers why they can use class syntax for iOS but not for Android.
Motivation: we wanted to keep V8 customization at minimum so we can achieve relatively feature parity by upgrading V8 engine as soon as possible.
So, now we know traversing V8 heap can be slow, what else? The current implementation is incomplete and case-by-case driven. This means that it is updated when there are important and common memory usage patterns. For example, currently we don’t traverse Map and Set objects.
Let’s see what can happen in practice. Create a default app.
tns create app1
Run the app and make sure it works as expected.
Now, we have to go through the process of designing a user scenario where the runtime will crash. We know that the current implementation doesn’t traverse Map and Set objects. So, we have to make Java object which is reachable only through, let’s say, Map object. This is only the first part of our exercise. We also must take care to make it reachable through a closure. Finally, we must give a chance for GC to collect it before we use it. So, let’s code it.
function crash() {
var m = new Map();
m.set('o', new java.lang.Object() /* via the map only */);
var h = new android.os.Handler(android.os.Looper.getMainLooper());
h.post(new java.lang.Runnable({
run: function() {
console.log(m.get('o').hashCode());
}
}));
}
That’s all. Finally, we have to integrate crash within our application. We can do so by modifying onTap handler in [proj_dir]/app/main-view-model.js as follows:
viewModel.onTap = function() {
crash();
gc();
java.lang.Runtime.getRuntime().gc();
this.counter--;
this.set("message", getMessage(this.counter));
}
Run the app and click the button. You should get error screen similar to the following one.
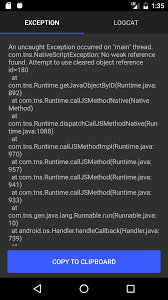
Motivation: we wanted to evolve V8 heap traversing on case-by-case basis in order to traverse as little as possible.
Understanding this memory usage pattern (create object, set up object reachability, GC and usage) is a simple but powerful tool. With the current implementation the fix for Map and Set is similar to this one. Also, realizing that in the current implementation the missing references to the captured objects is the only reason for this error is critical for any further changes. This is well documented in the form of unit tests.
So far we discussed the drawbacks of the current implementation. Let’s say a few words about its advantages. First, and foremost, it keeps the current memory management model familiar to the existing Java and JavaScript developers. This is important in order to attract new developers. If two technologies, X and Y, solve similar problems and offer similar licenses, tools, etc., the developers are in favor for the one with simpler “mental model”. While introducing alloc/free or try/finally approach is powerful, it does not attract new developers because it sets higher entry level, less explicit approach. Another advantage, which is mostly for the platform developers, is the fact that current approach aligns well with many optimizations that can be applied. For example, taking advantage (introducing) of GC generations for the means of NativeScript runtime. Also, it allows per-application fine tuning of existing V8 flags (e.g, gc_interval, incremental_marking, minor_mc, etc.). Tweaking V8 flags won’t have general impact when manual memory management is applied. In my opinion, tuning these flags is yet another way to help regular Joe shooting himself in the foot, but providing sane defaults and applying adaptive schemes very possible could be a huge win.
It is important to note that whatever approach is applied, this must be done carefully because of the risk of OOM exception. Introducing schemes like GC generation should consider the object memory weight. This will make obsolete the current approaches that use time and/or memory pressure heuristics. In general, such GC generation approach will pay off well.
I hope I shed more light on this challenging problem. Looking forward to see how the team is going to approach it. Good luck!