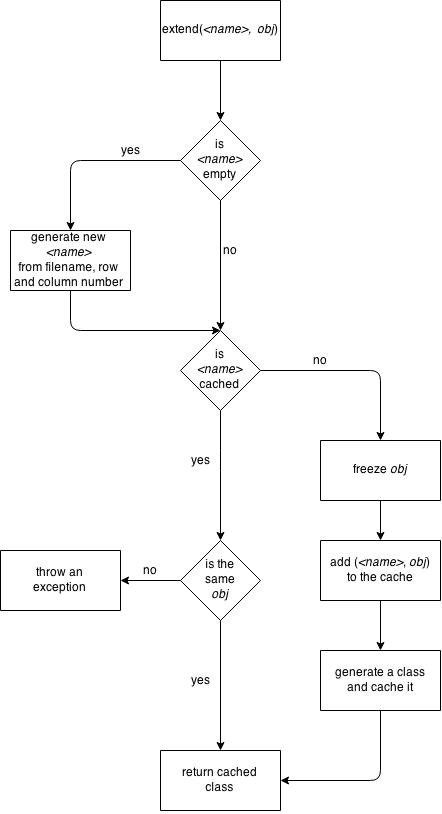
It’s more than 3 years since I started working on NativeScript. Working on an OSS project is different from anything I did before so I decided to share some of my experience. Here are some of the lessons I learned working on OSS and as usually happens all these lessons were discovered by many other people before.
Make an economic difference
This is a common characteristic of almost every successful OSS project. Take a look at Linux, Ruby on Rails, MySQL or Node.js for example. All these projects made an impact on our society for good reasons. They may change existing markets, create new jobs or simply make us more productive.
Technology that matters is technology that drives some economic difference.
Whatever is the OSS project you work on make sure it’s worth it.
Engage the community
Doing OSS project in isolation limits your chances to build a product that matters. Many OSS projects go in wrong direction without user feedback. OSS projects may fail for a lot of reasons: they do the wrong thing, solve the wrong problem or solve the right problem in non user friendly way. These issues can be prevented if a user community is in place. Building software for other users than yourself is challenging. Even if you have a clear vision what the project should be it is good idea to discuss it in public. Leaving “gaps” in your project gives chance for user contribution. Here is a quote from Christopher Alexander on this topic:
Master plans have two additional unhealthy characteristics. To begin with, the existence of a master plan alienates the users…. After all, the very existence of a master plan means, by definition, that the members of the community can have little impact on the future shape of their community, because most of the important decisions have already been made. In a sense, under a master plan people are living with a frozen future, able to affect only relatively trivial details. When people lose the sense of responsibility for the environment they live in, and realize that there are merely cogs in someone else’s machine, how can they feel any sense of identification with the community, or any sense of purpose there?
Second, neither the users nor the key decision makers can visualize the actual implications of the master plan.
Here is another observation, the Conway’s law, which in its simplified form states:
organizations which design systems … are constrained to produce designs which are copies of the communication structures of these organizations
In short, no matter how smart you are your solutions will be constrained by your understanding about the problem. Engaging more people on a problem can give you more perspectives on it, hence better chances to find broader solution.
Find your pace
I love the following comment on Linux 3.0 kernel because it captures an important aspect of OSS projects:
It’s hard to make revolutionary changes, especially when you have the open-source community making so many contributions. Just like a democratic political process, the changes are going to be incremental, but user driven. That’s why free software is so good.
Striving for innovation may cause as much damage as much your intention for good is. Often the push for novelty may be far less productive than what can be achieved by broadening participation. Achieving mass adoption in an incremental approach and solving the nowadays problems, often gives the most sustainable way for growth.
Learn from the others
Finally, I would like to comment on some of Eric S. Raymond’s lessons for creating good OSS. I am going to comment only on these that are confirmed by my experience.
- Every good work of software starts by scratching a developer’s personal itch.
I couldn’t agree more. Starting a project because you have a problem is one thing and starting a project because of me-too effect is another story. Be careful if you start a project just to chase the market. - Good programmers know what to write. Great ones know what to rewrite (and reuse).
Building your project around an existing one may give you a tremendous boost. You can take leverage on the existing community and shape your project quickly and efficiently. - If you treat your beta-testers as if they’re your most valuable resource, they will respond by becoming your most valuable resource.
While this is a common sense, I think is one of the most underestimated thing. Early adopters can give you valuable feedback and can become evangelists for your project. - The next best thing to having good ideas is recognizing good ideas from your users. Sometimes the latter is better.
I already touched this topic with Conway’s law. The more people are generating ideas the better are the chances for your project to succeed. - Often, the most striking and innovative solutions come from realizing that your concept of the problem was wrong.
We learn from our mistakes but often it is not that easy to see them. Having a healthy OSS community greatly improves the chances for someone to point you the mistake or make a code review. - Any tool should be useful in the expected way, but a truly great tool lends itself to uses you never expected.
I already touched this topic with Christopher Alexander’s quote. When designing a feature you rarely can predict all use cases. Engaging the OSS community can provide you with more perspectives on the problem so you can design better features. - Provided the development coordinator has a communications medium at least as good as the Internet, and knows how to lead without coercion, many heads are inevitably better than one.
It just says it all.