Mocking complements the test-driven development (TDD) allowing developers to write small and concise unit tests for components with external dependencies that would otherwise be hard or impossible to test. As the software becomes more and more distributed and loosely coupled, mocking becomes an intrinsic part of TDD process. While there are good tools and established best practices for mocking in .NET, most of the currently widely used approaches are imperative. Imperative code tends to be verbose, less expressive and describes how a mocking behavior is achieved rather what behavior is desired. On the other hand, nowadays new technologies make it possible to build declarative mocking tools and frameworks.
Let’s start with a few examples (I try to avoid artificially examples, e.g. ICalculator-like, because they don’t explain the properties of real projects). Suppose you work on a mobile social app that consumes external weather service. The app sends the current coordinates (latitude and longitude) and gets back JSON data as a string. You define the service interface as:
public interface IWeatherService
{
string GetCurrent(float latitude, float longitude);
}
The service implementation does a REST call to get the data. For my current location, the REST call looks like the following:
http://api.openweathermap.org/data/2.5/weather?lat=42.7&lon=23.3
Once the app gets the data it should suggest places where the user can meet with friends. Depending on the current weather, the app should suggest an indoor or outdoor place. A possible implementation of this feature may look like the following:
public enum Sky
{
Cloudy,
PartiallyCloudy,
Clear
}
public enum PlaceType
{
Indoor,
Outdoor
}
public class WeatherModel : Model
{
private readonly IWeatherService weatherService;
public WeatherModel(IWeatherService weatherService)
{
if (weatherService == null)
{
throw new ArgumentNullException("weatherService");
}
this.weatherService = weatherService;
}
public PlaceType SuggestPlaceType(float latitude, float longitude)
{
var sky = this.GetCurrentSky(latitude, longitude);
return sky.Equals(Sky.Clear)
? PlaceType.Outdoor
: PlaceType.Indoor;
}
private Sky GetCurrentSky(float latitude, float longitude)
{
var data = this.weatherService.GetCurrent(latitude, longitude);
dynamic json = JsonConvert.DeserializeObject(data);
var value = json.weather[0].main.Value as string;
var sky = (Sky)Enum.Parse(typeof(Sky), value);
return sky;
}
// the rest is omitted for brevity
}
The implementation is quite straightforward. It provides a simple design for dependency injection via WeatherModel constructor and SuggestPlaceType method keeps the logic simple by delegating most of the work to a private method.
As we said before, the implementation of IWeatherService does a REST call. This requires that the test server(s) should have internet connection available. This is a serious restriction because most test environments are not internet-connected.
To solve this issue we can use any modern mocking framework (e.g. Moq, JustMock, NSubstitute, FakeItEasy and so on). In this case I am going to use JustMock.
[TestMethod]
public void TestSuggestedPlaceType()
{
// Arrange
var weatherSvc = Mock.Create<IWeatherService>();
var latitude = 42.7f;
var longitude = 23.3f;
var expected = "{'coord':{'lon':23.3,'lat':42.7},'sys':{'country':'BG','sunrise':1380428547,'sunset':1380471081},'weather':[{'id':800,'main':'Clear','description':'Sky is Clear','icon':'01d'}],'base':'gdps stations','main':{'temp':291.15,'pressure':1015,'humidity':72,'temp_min':291.15,'temp_max':291.15},'wind':{'speed':1,'deg':0},'rain':{'3h':0},'clouds':{'all':0},'dt':1380439800,'id':6458974,'name':'Stolichna Obshtina','cod':200}";
Mock.Arrange(() => weatherSvc.GetCurrent(latitude, longitude)).Returns(expected);
// Act
var model = new WeatherModel(weatherSvc);
var suggestedPlaceType = model.SuggestPlaceType(latitude, longitude);
// Assert
Assert.AreEqual(PlaceType.Outdoor, suggestedPlaceType);
}
I prefer Arrange-Act-Assert (AAA) pattern for writing unit tests because it makes it simple and easy to read. As we can see, in this scenario the unit test is quite concise: 2 lines for the arrangement, 2 lines for the action,1 line for the assertion and a few lines for local variable definitions and comments. In fact, any modern mocking library can do it in a few lines. It doesn’t matter if I use JustMock or Moq or something else.
The point is, in such simple scenarios any mocking framework usage will result in simple and nice to read unit tests. Before we continue, I would like to remind you that both JustMock and Moq are imperative mocking frameworks. So are NSubstitute and FakeItEasy and many others. This means that we have explicitly to command the mocking framework how the desired behavior is achieved.
So far, we saw that imperative mocking frameworks do very well in simple scenarios. Let’s see an example where they don’t do well and see how declarative mocking can help. Suppose you work on invoice module for a CRM system. There is a requirement that the invoice module should send an email when there are more than 3 delayed invoices for a customer. A possible implementation may look as it follows:
public interface ISpecializedList<T>
{
void Add(T item);
void Reset();
uint Count { get; }
// the rest is omitted for brevity
}
public interface ICustomerHistory
{
ISpecializedList<Invoice> DelayedInvoices { get; }
// the rest is omitted for brevity
}
public class InvoiceManager
{
private readonly ICustomerHistory customerHistory;
public static readonly uint DelayedInvoiceCountThreshold = 3;
public InvoiceManager(ICustomerHistory customerHistory)
{
if (customerHistory == null)
{
throw new ArgumentNullException("customerHistory");
}
this.customerHistory = customerHistory;
}
public void MarkInvoiceAsDelayed(Invoice invoice)
{
var delayedInvoices = this.customerHistory.DelayedInvoices;
delayedInvoices.Add(invoice);
if (delayedInvoices.Count > DelayedInvoiceCountThreshold)
{
this.SendReport(invoice.Customer);
}
}
private void SendReport(Customer customer)
{
// send report via email
this.ReportSent = true;
}
public bool ReportSent
{
get; private set;
}
// the rest is omitted for brevity
}
Let’s write the unit test. I am going to use JustMock.
[TestMethod]
public void TestSendReportWhenDelayOrderThresholdIsExceeded()
{
// Arrange
var history = Mock.Create<ICustomerHistory>();
uint count = 0;
Mock.Arrange(() => history.DelayedInvoices.Add(Arg.IsAny<Invoice>())).DoInstead(new Action(() =>
{
Mock.Arrange(() => history.DelayedInvoices.Count).Returns(++count);
}));
// Act
var invoiceMananger = new InvoiceManager(history);
invoiceMananger.MarkInvoiceAsDelayed(new Invoice());
invoiceMananger.MarkInvoiceAsDelayed(new Invoice());
invoiceMananger.MarkInvoiceAsDelayed(new Invoice());
invoiceMananger.MarkInvoiceAsDelayed(new Invoice());
// Assert
Assert.IsTrue(invoiceMananger.ReportSent);
}
This time the unit test looks quite complicated. We have to use DoInstead method to simulate the internal workings of ISpecializedList<T> implementation. Said in another words we have code duplication. First, there is a code that increments the Count property of ISpecializedList<T> implementation we use in production. Second, there is a code that increment the Count property in our test for the sole purpose of the test. Also, note that now we have count local variable in our test.
Let’s compare the two scenarios and see why the last test is so complicated. In the first scenario we don’t have a mutable object state while in the second one we have to take care for the Count property. This is an important difference. Usually a good program design says that a method with a return value doesn’t change the object state, while a method without a return value does change the object state. After all, it is common sense.
Suppose we have to write a unit test for the following method:
public void CreateUser(string username, string password) { ... }
This method doesn’t return a value. However, it changes the system state. Usually, when we write a unit test for void method we assert that the system is changed. For example, we can assert that we can login with the provided username and password.
Another option is to change the method signature so the method returns a value:
public bool /* success */ CreateUser(string username, string password) { ... }
// or
public int /* user id */ CreateUser(string username, string password) { ... }
However this is not always possible or meaningful.
So, we see that mocking even a simple interface like ISpecializedList<T> complicates the unit tests. This is a consequence of imperative mocking approach. Let’s see a hypothetical solution based on FakeItEasy syntax.
[TestMethod]
public void TestAddItem()
{
// Arrange
var list = A.Fake<ISpecializedList<Invoice>>();
A.CallTo(() => list.Add(A<Invoice>.Ignored).Ensures(() => list.Count == list.Count + 1);
// Act
list.Add(new Invoice());
list.Add(new Invoice());
list.Add(new Invoice());
// Assert
Assert.AreEqual(3, list.Count);
}
In this case we removed the need of count local variable and made the test shorter and a more expressive. The Ensures method accepts a lambda expression that describes the next object state. For example, we can arrange Reset method as follows:
A.CallTo(() => list.Reset()).Ensures(() => list.Count == 0);
Let’s see two more examples. We can arrange a mock for IDbConnection as follows:
IDbConnection cnn = ...;
A.CallTo(() => cnn.CreateCommand()).Returns(new SqlCommand());
A.CallTo(() => cnn.Open()).Ensures(() => cnn.State == ConnectionState.Open);
A.CallTo(() => cnn.Close()).Ensures(() => cnn.State == ConnectionState.Closed
&& A.FailureWhen<InvalidOperationException>(() => cnn.BeginTransaction()));
A.CallTo(() => cnn.Database).FailsWith<NotImplementedException>();
A.CallTo(() => cnn.BeginTransaction()).FailsWhen<InvalidOperationException>(() => cnn.State != ConnectionState.Open);
This code fragment shows how we can describe the state machine behind IDbConnection instance. Similarly, we can arrange a mock for TextReader as follows:
TextReader reader = ...;
A.CallTo(() => reader.Read()).Requires(() => reader.CanRead);
A.CallTo(() => reader.Read()).Returns(0);
A.CallTo(() => reader.Close()).Ensures(() => A.FailureWhen<InvalidOperationException>(() => reader.Read()));
A.FailureWhen<Exception>(() => reader.ReadBlockAsync(null, 0, 0));
While a fluent API can help with declarative mocking it surely has limits. Both Requires and Ensures methods describe invariants but the lambda expressions become harder to read when they grow in size. So I started looking for improvements.
First, I decided to try Roslyn. It turns out that Roslyn is quite good framework for my purposes. My current approach is to define mock types as regular classes (I find some limitations of this approach and more research is needed). Instead of using fluent API I can define a mock type in the source code.
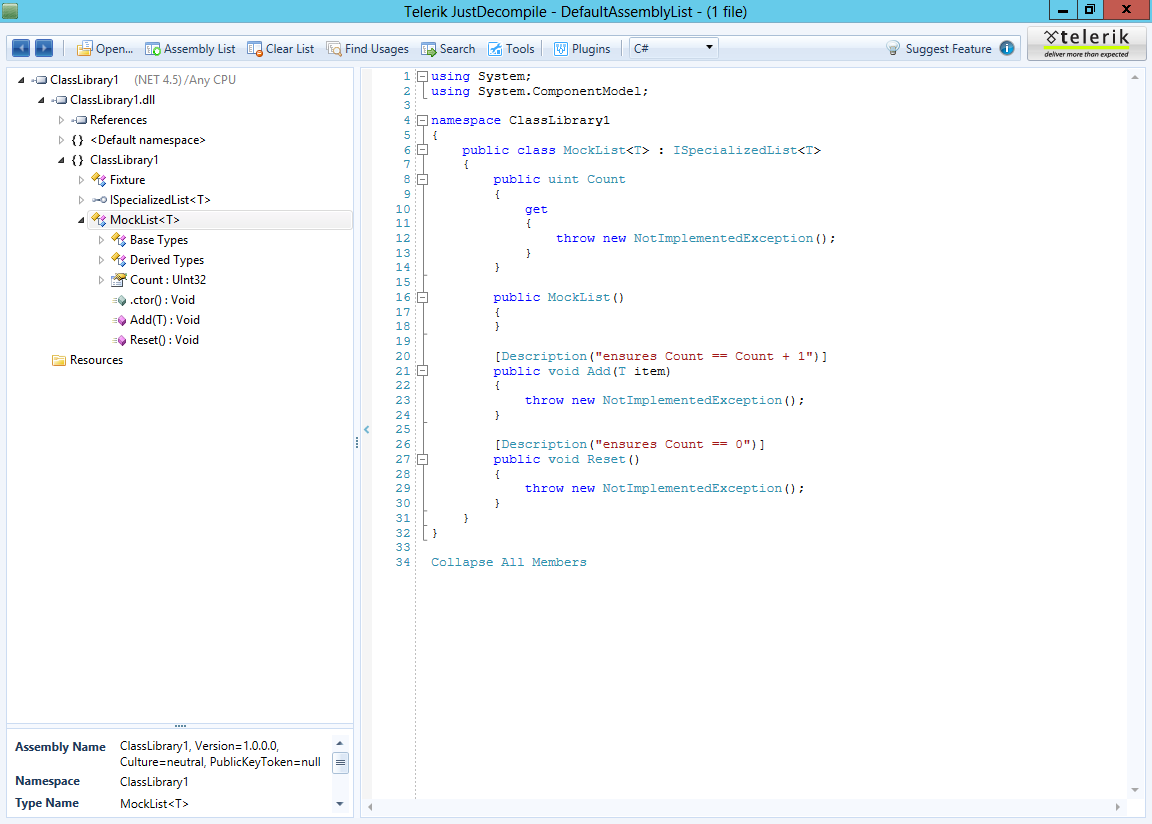
public mock class MockList<T> : ISpecializedList<T>
{
public void Add(T item)
ensures Count == Count + 1;
public void Reset()
ensures Count == 0;
public uint Count
{
get;
}
}
I borrowed ensures clause from Spec# and added mock modifier to the class definition. Then I used Roslyn API to hook and emit a simple throw new NotImplementedException(); for every method.
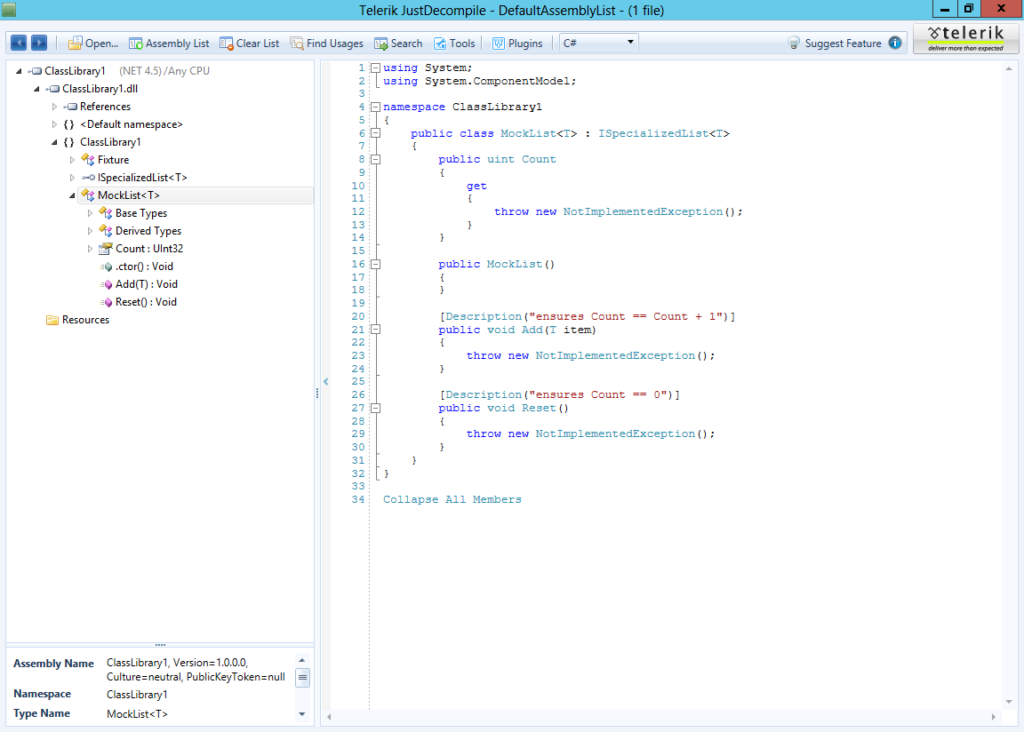
I also emitted DescriptionAttribute for every ensures clause. I guess, it will be better to emit a reference to a custom attribute defined in another assembly but for now I decided to keep it simple. Now we can rewrite the previous TestAddItem test as follows:
[TestMethod]
public void TestAddItem()
{
// Arrange
var list = new MockList<Invoice>();
// Act
list.Add(new Invoice());
list.Add(new Invoice());
list.Add(new Invoice());
// Assert
Assert.AreEqual(3, list.Count);
}
With the current implementation this test will fail with NotImplementedException but the test itself is short and easy to read. For further development I see two options. The first one is to make Roslyn to emit the correct ILASM corresponding to the expressions defined via requires and ensures clauses. The second option is to emit an interface rather a class and to keep requires and ensures clauses encoded as attributes. Then, at runtime the mocking API can create types that enforce the defined invariants. I think the second option is more flexible than the first one.
Besides Roslyn, there is another approach that can make mocking easier. Recently I came upon the concept of prorogued programming. Using this technique the developer can train the mocks used in the unit tests so that the desired behavior is achieved during the test runs. While this approach may seem semi-automated I find it very attractive. I think it has a lot of advantages and if there is a good tooling support it may turn out this is a better way to go.
What’s next? I will research the Roslyn approach further. There are two options:
- (static) using Roslyn API to emit ILASM at compile time
- (dynamic) using Roslyn to emit interfaces and metadata and then using mocking API at runtime to provide the actual implementation
Both options have tradeoffs and a careful analysis is needed. Prorogued programming seems very suitable technique to make mocking easier so I need to investigate it further. Stay tuned.
Further reading: